AI as Autonomous Vehicles: Can We Detect When They Fail?
Most people have an opinion about self-driving cars (i.e. Waymos, Tesla, and their kin). And if you push on it, the discomfort usually isn't about whether the car will fail; it's about how it will fail. We've spent a century learning to read each other on the road. The driver drifting in their lane, the hesitation at the merge, the too-late brake — we recognize those patterns and adjust without thinking. An autonomous vehicle fails differently. It's perfectly smooth right up until it isn't, and the error, when it comes, doesn't look like anything we've learned to watch for. The failure modes are alien, and that's what actually unsettles people.
It turns out the same dynamic is playing out, far less visibly, inside the industries responsible for the drugs you take and the medical devices you depend on. As AI systems enter regulated life sciences — classifying manufacturing deviations, reviewing clinical data, flagging quality signals — the major question regulators and quality teams are wrestling with isn't whether these systems fail. It's whether anyone will notice when they do.
Take some of the failure modes we’ve seen with autonomous vehicles, sometimes even leading to recalls:
Approximately 3,800 Waymo fifth-and sixth-generation robotaxis were recalled in May due to vehicles driving onto a flooded road or into standing water during heavy rain in San Antonio. The interim flood patch failed, and a second flooding incident occurred in Atlanta less than two weeks after the recall. The safety fix itself needed additional validation.
Around another 3,900 Waymo robotaxis were recalled in June after some cars drove into closed freeway construction zones.
The solution? Waymo itself states that it is focused on “additional software safeguards” and “mitigations”, such as specifying where its robotaxis are allowed to operate during severe weather conditions, to prevent the vehicles from entering flooded areas in the first place.
Circling back to our AI systems being implemented in pharma, let’s take a closer look at a common LLM use case like deviation triage. Some of the failure modes we’ve seen include:
“Looks-right-but-wrong” outputs: for example, a root cause analysis that reads fluently and confidently, but has no bearing in the data from the deviation incident itself.
“Recognition errors”: for example, the operator refers to the Filter Integrity Tester by its acronym “FIT”, but the model does not recognize “Filter Integrity Tester” and “FIT” as the same entity.
The solution? Software safeguards and mitigations, in the context of our ChatGPT-era models in GxP settings, in the form of what we call a “harness.” The harness essentially functions as the “safety scaffolding” around the model, providing controls against these unpredictable failure modes: ideally, when properly validated, keeping us from veering off the road.
The Validated Unit: Model x Harness x COU
The initial wave of large language models (ChatGPT, Claude, Copilot) emphasized performance of the frontier model itself. The next wave will be characterized by everything surrounding the model: the context-of-use (discussed in a previous piece in this series “Context is King: Why AI Validation is Driven by Use Context”) and the harness.
For those of us who work in validation/quality/IT roles, the key concept here is that the unit of regulation is the model × harness × context-of-use configuration (plus the HITL, which will be covered in a separate piece), not the model alone. The harness is where the determinism actually lives.
Both the runtime and validation layers become the wrappers around a probabilistic system (large language models, agents, etc.). Both instruments have the same surface area (inputs, intermediate states, outputs, tool calls). Both need to capture enough to reconstruct what happened. The difference is mostly in what you do with the captured data: the agent harness uses it for runtime control (guardrails, retries, fallback logic), and the validation harness uses it for post-hoc investigation and regulatory evidence. But the capture layer underneath is largely the same.
This piece argues that the agent harness and the validation harness should be the same harness, with different views on top. Right now, organizations building agentic systems in regulated environments are often building two parallel stacks: the ML team builds an agent harness for orchestration, the QA team builds (or asks for) a validation harness for evidence. They capture overlapping but inconsistent data, they store it in incompatible formats, and when a deviation occurs the investigation has to reconcile two sources of truth that should have been one. That's an architectural failure, and it's expensive.
A unified capture layer collapses this divergence: same prompts, same context, same model snapshots, same tool traces, same outputs, all written to one immutable store with consistent schema and lineage.
The runtime control plane (the agent-harness view) uses the captured data for things that need to happen in milliseconds: guardrail evaluation, output validation, retry decisions, human-in-the-loop escalation. It's optimized for latency and operational reliability.
The assurance control plane (the validation-harness view) uses the same captured data for things that happen on a much slower clock: deviation investigation, periodic review, drift detection, audit response, regulatory submission. It's optimized for completeness, traceability, and evidentiary weight.
The capture is one thing; the queries above it are many.
The Validation Question & Where the Harness Fits
To understand why the harness—not the model alone—must be included in the validation unit, consider two competing architectures designed for the exact same context of use: classifying a deviation. The purpose of this example is to illustrate why the model alone cannot be the unit of validation. The validation boundary must extend to the prompt, the configuration, the harness around the model, and the human interface.
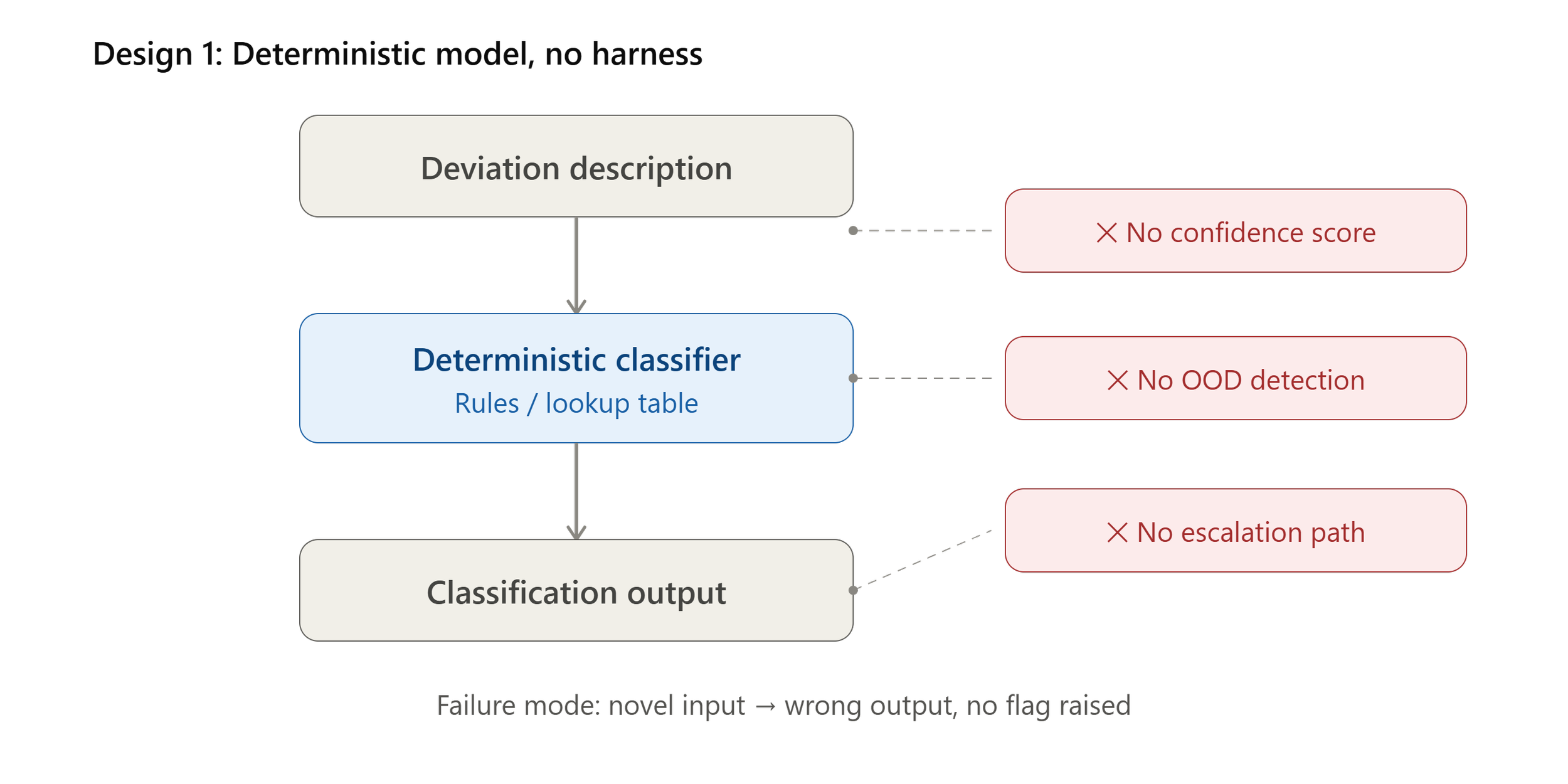
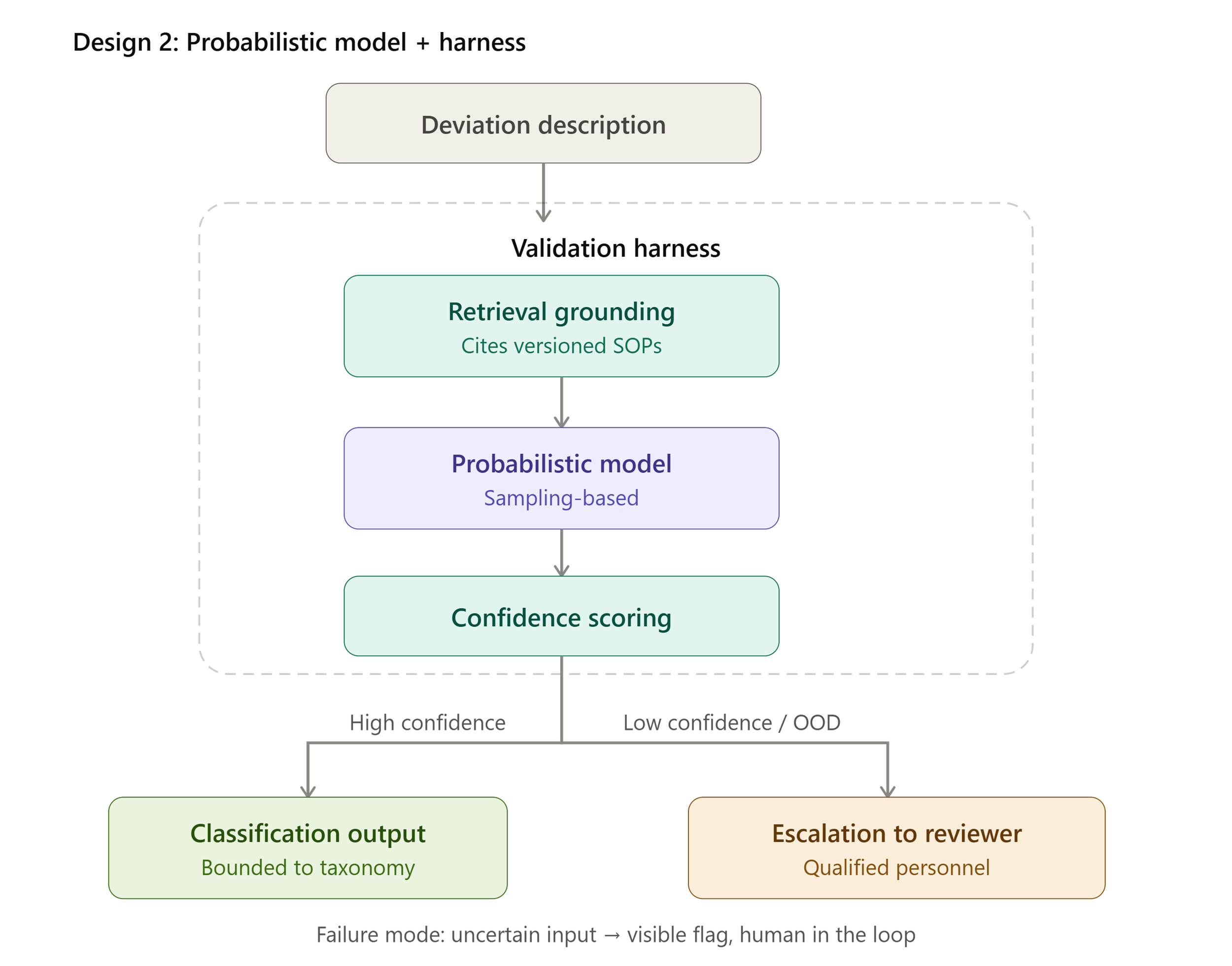
A deterministic model surrounded by no harness is not automatically more compliant than a probabilistic model with a harness. Reproducibility is not interchangeable with correctness. The example below, separated into two architectural designs, demonstrates why.
Architectural Design 1: Deterministic Model (Ex: Rules Engine) - Harness
Architectural Design 2: Probabilistic Model (Ex: Frozen LLM) + Harness
Ontology: The Vocabulary Problem
The harness encodes ontology operationally: tool schemas define the action vocabulary, system prompts define the role vocabulary, retrieval indices define the knowledge vocabulary, and guardrail evaluators define the bounds vocabulary. The harness is where ontology stops being a document and starts being enforced. It intercepts the model's output before it reaches the reviewer or the regulatory record, translates it into a structured representation, increasingly, a knowledge graph, and runs it against the pre-validated ontology. When the output asserts a relationship that violates the ontology's semantic rules — a classification that contradicts the controlled taxonomy, a causal claim linking two entities the ontology says cannot be linked — the harness catches it. It doesn't matter how fluent or confident the model sounds. The ontology says "No."
But it's worth being precise about what this layer does and doesn't catch, because overstating it is how you lose a regulator's trust. An ontology check catches contradiction: outputs that violate an encoded rule. It does not, on its own, catch plausible-but-ungrounded: the fluent root cause analysis from our opening example that reads perfectly, violates no semantic rule, and simply has no basis in the deviation data. That failure passes the ontology cleanly, because nothing is contradicted; something is just invented.
This is why the harness is layered rather than singular. The ontology narrows the failure surface at the guardrail layer. Retrieval grounding constrains the model to versioned source material, so there's less room to invent in the first place. Confidence scoring and human review catch the plausible-but-wrong residue that slips past both. No single control closes the gap; the architecture does.
Anthropic's own data team makes this point empirically. In a June 3rd 2026 blog on running self-service analytics with Claude (“How Anthropic enables self-service data analytics with Claude” retrieved from https://claude.com/blog/how-anthropic-enables-self-service-data-analytics-with-claude), they report that giving the model raw access to thousands of historical queries, where the correct answer was already present roughly 80% of the time, moved accuracy by less than a single percentage point. The substantive improvements come from the governed-context loop, not the model. Without skills, Claude's accuracy on analytics questions didn't exceed 21% on its evals; with skills it runs consistently above 95% (in aggregate), and around 99% in some domains. Anthropic describes a “skill” as “procedural knowledge: which sources to consult in what order, how to navigate ambiguous data, and what a finished analysis looks like.” This is analogous to the harnesses around LLMs in GxP settings.
Anthropic is also candid about the limit: silent failures — confident, plausible, wrong answers that go unchallenged — remain unsolved. That's the honest boundary of what any harness delivers today: it shrinks the space where silent failure can hide; it doesn't yet eliminate it. This is where multi-layered architecture earns its keep.
As Alex Moskowitz of the National Center for Ontological Research phrases it: "We're in a time where LLMs and AI are expected to produce a certain outcome, and often they can. What they cannot produce, for places that need to trust their outcomes, is a defensible one, because the output is a probabilistic guess with no trail behind it."
The ontology doesn't make a probabilistic system deterministic. It makes it bounded. And a bounded system whose failures are detectable is the defensible thing in regulated pharma.
The Harness as the Control Surface
Four properties are relevant here: deterministic, inspectable, testable, auditable. The harness can carry regulatory load that Copilot or ChatGPT cannot. This is where the ontology shines: per Moskowitz, “to build an ontology is to describe what actually exists in a domain, with logical constraints and definitions a system can operationalize. That is what lets you audit an answer and trace the reasoning back through the exact trail it took.” A risk-based approach allows for scaling the type and depth of the documentation and architecture to the consequence and context-of-use.
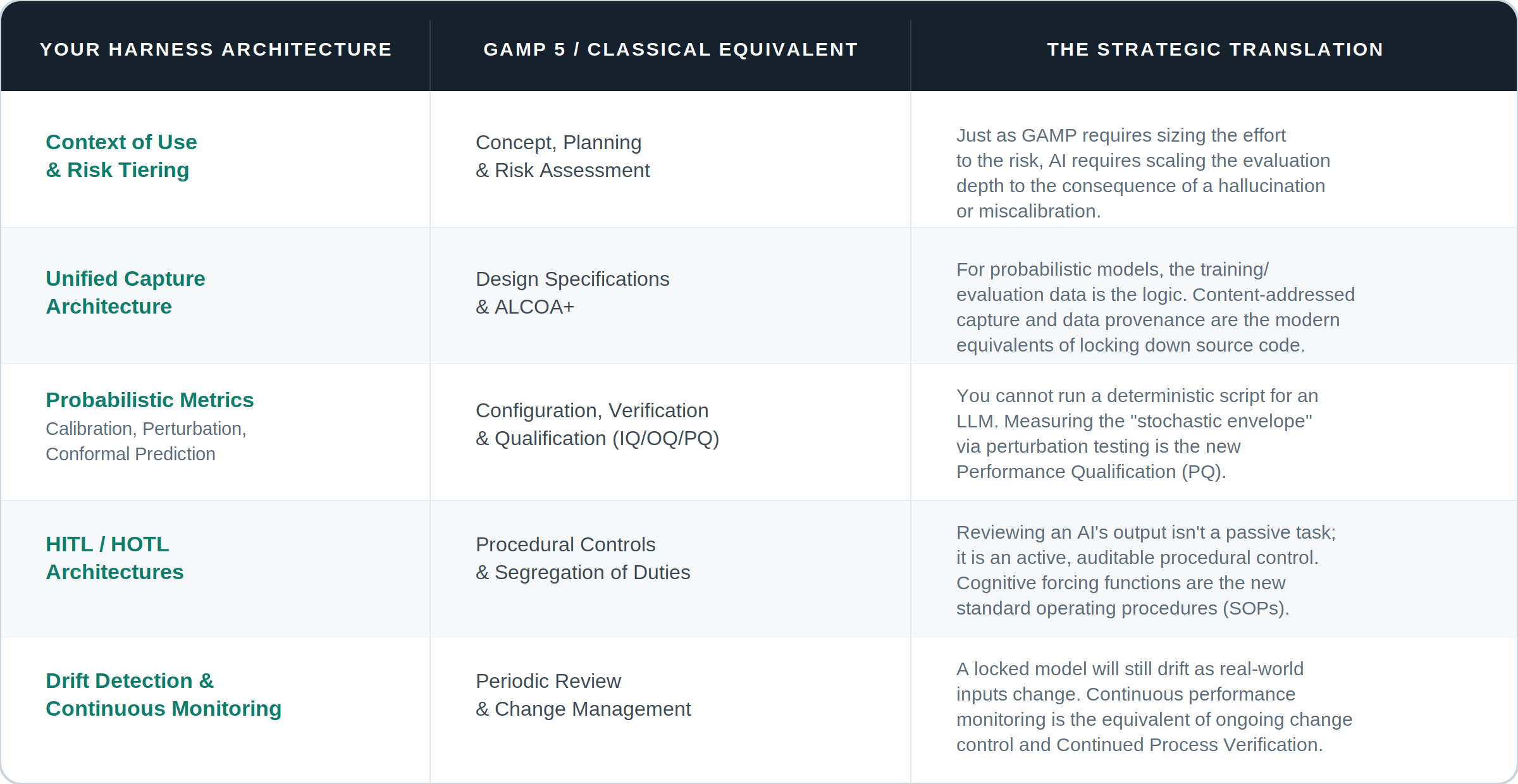
Moskowitz makes a related point about where these systems are heading: the field is moving toward GraphRAG and then knowledge graphs, which is the right direction. But a graph is only as good as the meaning underneath it. When a system has to disambiguate harder data, recognize what kind of thing something is, catch a contradiction, or say "not determined," that judgment doesn't come from the graph. It comes from the ontology beneath it: the logical definitions a machine can actually reason with.
But an ontology only carries regulatory weight if every check it performs is captured: which is the whole argument of this piece. The ontology is one layer the harness enforces; the unified capture layer is what makes that enforcement inspectable after the fact. When the ontology says "No," that "No" has to land in the same immutable store as the prompt that provoked it, the retrieved sources, the confidence score, and the reviewer's disposition. A rule that fires without a trace is an opinion. A rule that fires into the capture layer is evidence.
Engine, chassis, road. The work has been sitting in the harness the whole time.